DERIVA is a suite of tools and services that are designed to significantly reduce the overhead and complexity of creating and managing complex, big datasets. DERIVA provide a digital asset management system for scientific data to streamlines the acquisition, modeling, management and sharing of complex, big data, and provides interfaces so that these data can be delivered to diverse external tools for big-data analysis and analytic tools.
DERIVA is not intended to work "out of the box" but rather can be easily configured to adapt to a wide variety of different data types and use cases. We are currently working on preconfigured versions of DERIVA services to accommodate specific usage scenarios, such as PheWAS.
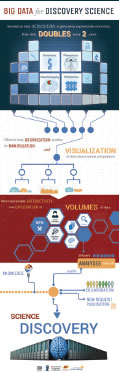
The components of the DERIVA ecosystem are shown in the figure below:

Get Latest ERMrest Software Get Latest Chaise Software Get Latest IObox Software Get Latest Hatrac Software ABIDE Data Catalog
The Deriva tools have been used for the PheWAS approach use case. ABIDE data can be explored on the Deriva system by clicking on this link.