On February 23rd and February 24th, BDDS researchers reviewed various new tools and methodologies for analyzing and managing large data sets as well as workflows incorporating many of the BDDS software packages. The BDDS researchers also discussed future education and training opportunities to publicize BDDS tools and approaches to the scientific community. The annual All Hands Meeting was at the USC Stevens Neuroimaging and Informatics Institute in Los Angeles.
About 20 researchers at the 2016 Society for Neuroscience meeting were drawn to a BDDS training session, Scientific Knowledge Discovery over Big Data, on November 17.
See full event details here.
Download Slides Download Flyer


BDDS was a key collaborator in the 2016 BrainHack LA, which attracted a healthy turnout at the USC Information Sciences Institute on Nov. 10-12.






BDDS tools, in particular minimal viable identifiers (minid) and BD Bags, were highlighted at a tutorial for ACM-BCB conference in Seattle in October. About 20 researchers participated in a highly interactive session with BDDS researchers and tools developers.

On March 3 and 4, BDDS researchers gathered in at the USC Keck Medical Center in Los Angeles to plot the course of the project over the next year. The BDDS researchers demonstrated tool sets and how they are integrated into the evolving BDDS platform as well as training and other opportunities to assist the biomedical and computer science research community.




Presenter: Michael D'Arcy, Ph.D. and Carl Kesselman, Ph.D.
Presenter: Naveen Ashish, Ph.D.
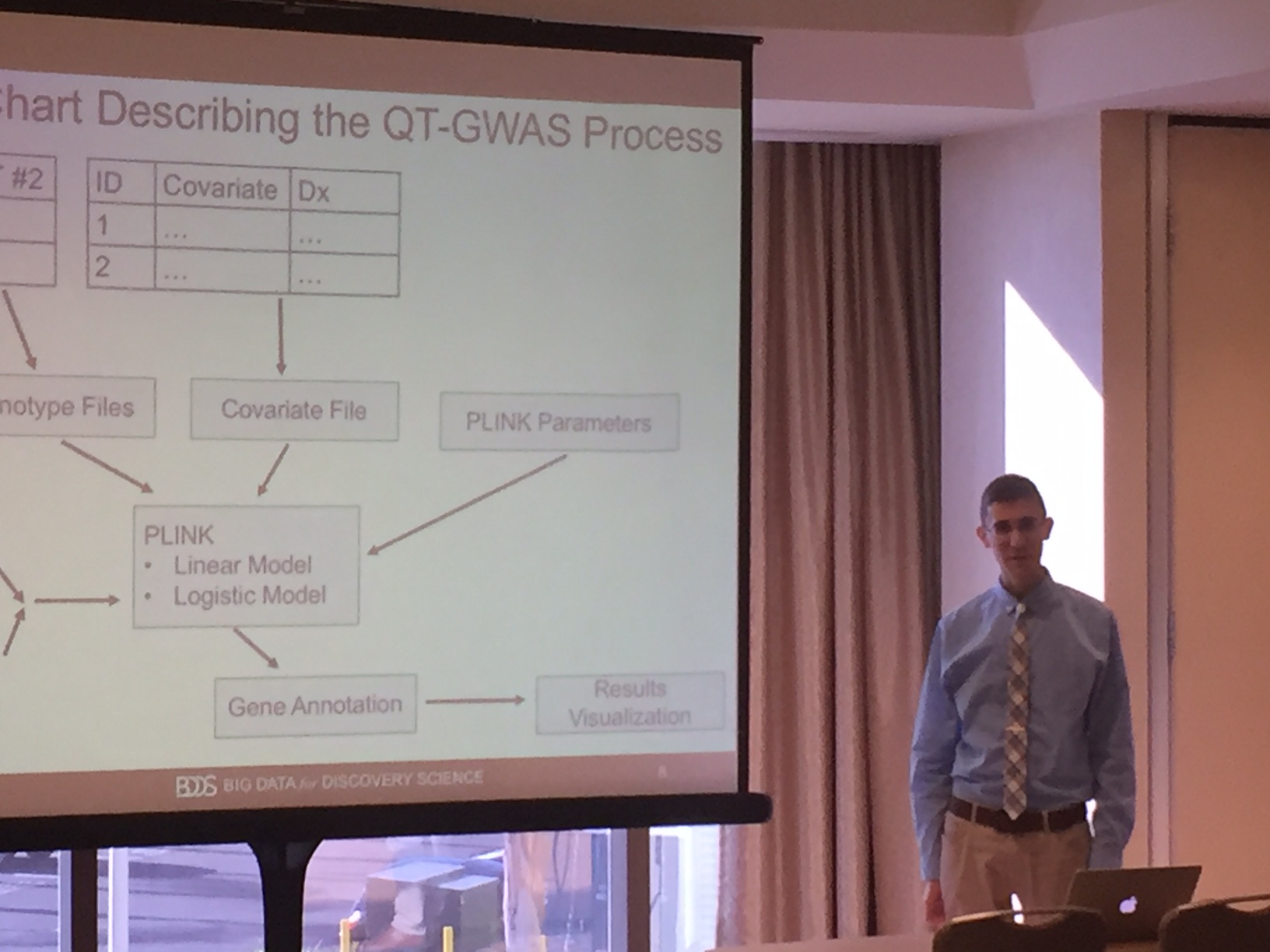
Presenter: Yonggang Shi, Ph.D. and Junning Li, Ph.D.
Presenter: John D. Van Horn, Ph.D.
Presenter: Kristi Clark, Ph.D.
Advanced Neuroimaging, Informatics, and Genomics Computing (September 11, 2015): This day-long event will include paired
training and application demonstrations on using different graphical and script-based pipeline workflow architectures to
manage, process, analyze and visualize large volumes of neuroimaging and genetics data. Attendees will learn to use several
concrete end-to-end pipeline workflow solutions for brain imaging (sMRI, fMRI, DTI), proteomics, and
phenotypic (demographic, genetic, clinical) data in development, aging and pathology.
Download Flyer
Presenters: Neda Jahanshad, Ph.D., Derreck Hibar, Ph.D., and Meredith Braskie, Ph.D.
The SPC is pleased to offer a four-day intensive in the use of a suite of open-source software tools designed for the analysis, validation, storage and interpretation of data obtained from large-scale quantitative proteomics experiments using stable isotope labeling method, multi-dimensional chromatography and tandem mass spectrometry. Through daily lectures and tutorials, each course participant should become proficient in the use of the tools.
Prerequisites
Prerequisite for participation in the course is a demonstrated understanding in the operation of tandem mass spectrometers, the basic structure and interpretation of peptide MS/MS spectra and proficiency in the use of computers. A commitment to attend the entire course is also required.
Details
Registrations must be completed by September 8, 2015.
Location
University of British Columbia
Michael Smith Laboratories
(2185 East Mall)
Vancouver, B.C., Canada
Dates
Tuesday, September 22, 9:00 am through Friday, September 25, 5:00pm.
* Participants must commit to attending the entire course and bring their own laptop.
Details and registration can be found here.
Course Objective
Big Data analysis has become central to the discovery process in various scientific domains. Challenges however remain in managing, moving, sharing and analyzing large data sets. The use of public cloud services to host sophisticated scientific data and software is transforming scientific practice by enabling broad access to capabilities previously available only to the few. The primary obstacle to more widespread use of public clouds to host scientific software ("cloud-based science gateways") has thus far been the considerable gap between the specialized needs of science applications and the capabilities provided by cloud infrastructures. In this talk, we describe a domain-independent, cloud-based scientific data services platform that combines Globus, Galaxy and Amazon Web Services cloud to manage, transfer, share and analyze big data sets. In addition to describing the capabilities, we will also describe use cases and success stories from life sciences domain
Location
The University of Chicago
Section on Statistical Computing
Online
Course Objective
The multi-dimensional characteristics of "Big Data" are defined as data size, incompleteness, incongruency, complex representation, multiscale nature, and heterogeneity of its sources. Big Data is effectively a messy collage of fragmented "conventional data" representing alternative views of the same complex natural process inspected through a multispectral prism. There are many statistical challenges associated with interpreting Big Data (e.g., its sparse and discordant format, designing robust data-representation/modeling strategies, error estimation). We will discuss several examples of high-throughput data analytics and model-free Inference and explore principles of distribution-free and model-agnostic methods for scientific inference based on Big Data sets. Compressive Big Data analytics (CBDA) is an idea for iteratively generating random (sub)samples from the Big Data collection and using classical techniques to develop model-based or non-parametric inference. CBDA repeats the (re)sampling and inference steps many times, and uses bootstrapping techniques to quantify probabilities, estimate likelihoods, or assess accuracy of findings. (Session link http://goo.gl/75FygQ)
Hyatt Regency Resort and Spa, Huntington Beach, CA
A highly interactive opportunity to present your
software, big data discoveries, and big data resources
and to discuss how to leverage our California-based
BD2K efforts into further consortia activities for largescale
biomedical science and training.
JW Marriott Desert Springs Resort, Palm Desert, CA
A highly interactive opportunity to present your
software, big data discoveries, and big data resources
and to discuss how to leverage our California-based
BD2K efforts into further consortia activities for largescale
biomedical science and training.
Hyatt Vineyard Creek Resort, Santa Rosa CA
A highly interactive opportunity to present your
software, big data discoveries, and big data resources
and to discuss how to leverage our California-based
BD2K efforts into further consortia activities for largescale
biomedical science and training.