Problem
Solution
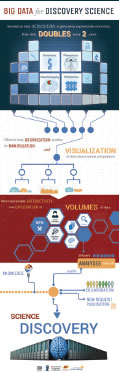
Our regularized linear models, machine learning tools, and high-throughput computational infrastructure enable efficient and reproducible (near) real-time processing, analysis and prediction using extremely large, complex and heterogeneous datasets. This enables open-science discovery, tool interoperability, and advanced statistical analysis that can be generalized to many big biomedical data-intense studies.
Result
We have built a generic machine learning based infrastructure for modeling and interrogation of diverse arrays of data-intense biomedical and healthcare challenges. We validated the technique on neuroimaging-genetic studies throughput the age spectrum in health and disease. BDDS tools such as Deriva, BDBags and Minids are being used by this project.
Reference
Methodological challenges and analytic opportunities for modeling and interpreting Big Healthcare