DERIVA (ERMrest, Chaise, Hatrac,and IOBOX), BDDS Data Repository, TPP, GEM
DERIVA (ERMrest, Chaise, Hatrac,and IOBOX), BDDS Data Repository, TPP, GEM
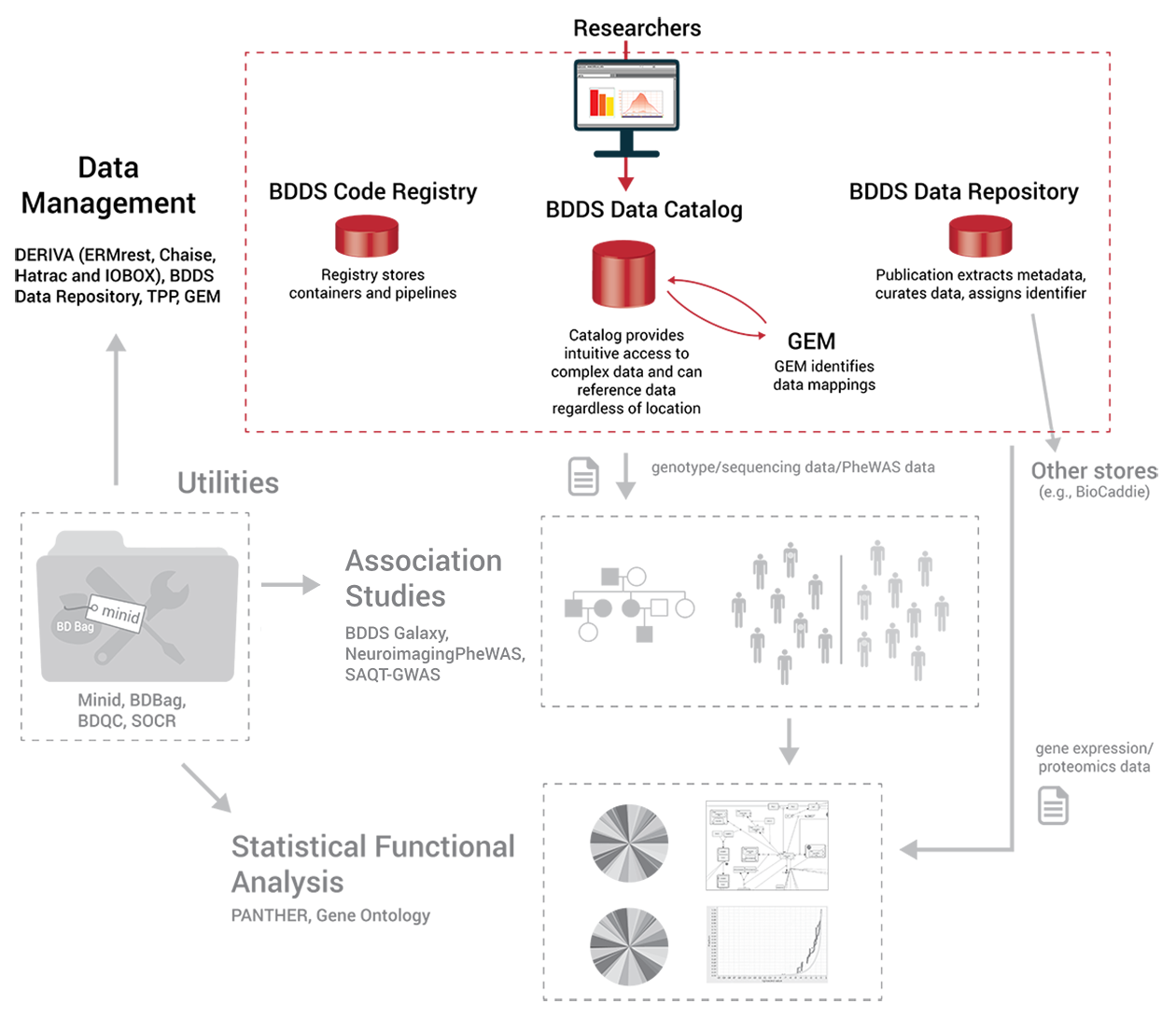
BDDS data processing sub-system is not one, but, a combination of various data stores, applications, utilities, web services and indexes for researchers and biologists to analyze, aggregate, collaborate and make correlations on big data. At the center of the BDDS data processing sub-system, is DERIVA, a suite of tools and services for managing large data. Researchers can import data into the DERIVA system and uncover correlations in large data sets that are not obvious. The data can be exported to the BDDS Data Repository where large sets of related data can be grouped together and labelled. In the Data Repository, related data is grouped together and stored as datasets, which is different from traditional RDBMS. The data in the Repository can be exported to BioCaddie where it can be indexed, allowing other users to discover it and link back to the Repository. The Trans-Proteomic Pipeline can be used to identify and quantify peptides and proteins from mass-spectrometry data for loading into a datastore or expression analysis.